linux怎么用多个gpu跑
时间:2023-05-29 来源:网络 人气:
众所周知,GPU可以加速各种计算任务。但是,当我们需要更快的计算速度时,单个GPU就不再足够了。那么,如何在Linux上使用多个GPU呢?这篇文章将为您解答。
安装驱动程序
首先,您需要确保所有GPU都已正确安装并配置好驱动程序。通常情况下,您可以通过以下命令来检查:
lspci|grep-invidia
如果您的系统中有多个NvidiaGPU,则应该看到多行输出。
接下来,您需要安装适合您的GPU的Nvidia驱动程序。这可以通过以下命令完成:
sudoapt-getinstallnvidia-driver-[version]
请注意,在这里,“[version]”是您要安装的驱动程序版本号。例如,“nvidia-driver-460”。
安装CUDA
要在Linux上使用多个GPU,您还需要安装CUDA工具包。CUDA是一个用于NvidiaGPU的并行计算平台和编程模型。
首先,从Nvidia官网下载适合您的CUDA版本。然后运行以下命令以安装:
sudodpkg-icuda-repo-[version].deb
sudoapt-getupdate
sudoapt-getinstallcuda
请注意,在此处,“[version]”是您下载的CUDA版本号。
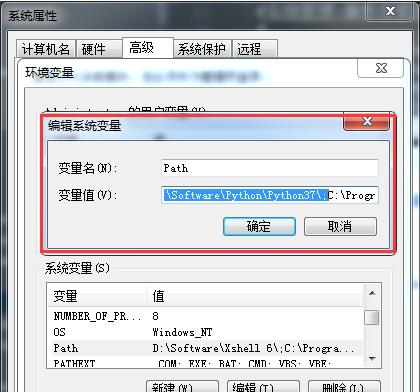
设置环境变量
完成CUDA的安装后,您需要将CUDA的c1111bd512b29e821b120b86446026b8目录添加到PATH环境变量中。这可以通过编辑.bashrc文件来完成:
nano~/.bashrc
在文件末尾添加以下行:
exportPATH=/usr/local/cuda-[version]/c1111bd512b29e821b120b86446026b8${PATH:+:${PATH}}
exportLD_LIBRARY_PATH=/usr/local/cuda-[version]/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
请注意,在这里,“[version]”是您安装的CUDA版本号。
使用多个GPU
现在,您已经在Linux上正确安装了多个GPU和CUDA。接下来,您可以使用以下代码片段来利用所有GPU进行计算:
python
importtensorflowastf
gpus=tf.config.experimental.list_physical_devices('GPU')
ifgpus:
try:
#设置为多GPU模式
forgpuingpus:
tf.config.experimental.set_memory_growth(gpu,True)
logical_gpus=tf.config.experimental.list_78ae2000a3964dd5a903ab9fc5f460f8_devices('GPU')
print(len(gpus),"PhysicalGPUs,",len(78ae2000a3964dd5a903ab9fc5f460f8_gpus),"LogicalGPUs")
exceptRuntimeErrorase:
#异常处理
print(e)
这将检测系统上的所有GPU,并启用TensorFlow以使用它们。
总结
本文介绍了如何在Linux上使用多个GPU进行计算。首先,您需要安装并配置好所有GPU的驱动程序和CUDA工具包。然后,您可以使用TensorFlow等库来利用所有GPU进行计算。
虽然这只是一个简单的示例,但它可以为您提供一个良好的起点,以便您可以在自己的项目中使用多个GPU。
imtoken钱包:https://cjge-manuscriptcentral.com/software/5276.html
相关推荐


教程资讯
教程资讯排行

系统教程
-
标签arclist报错:指定属性 typeid 的栏目ID不存在。