Hadoop生态系统的核心组件
时间:2023-10-18 来源:网络整理 人气:
大数据生态系统是一个庞大而复杂的系统,由多个组件和工具组成。它提供了处理和分析大规模数据集的能力,为企业和组织带来了巨大的商业价值。
1. Hadoop
Hadoop是大数据生态系统的核心组件之一。它是一个开源的分布式计算框架,可以在成百上千台服务器上同时处理海量数据。Hadoop的分布式文件系统HDFS可以存储PB级别的数据,并且具有高可靠性和容错性。
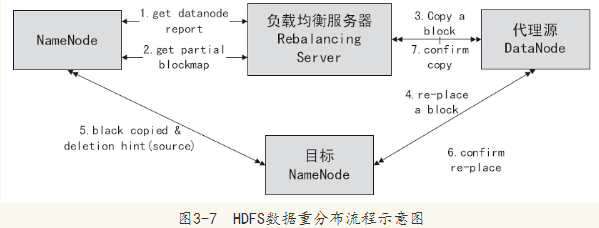
2. MapReduce

MapReduce是Hadoop中的另一个重要组件。它是一种编程模型,用于将大规模数据集分解成小块,并在集群中并行处理这些小块。MapReduce通过将计算任务分发到不同的节点上,并将结果合并起来,实现了高效的数据处理和分析。

3. Spark
Spark是一个快速而通用的大数据处理引擎。与传统的MapReduce相比,Spark具有更好的性能和灵活性。它支持多种编程语言,包括Scala、Java和Python,并提供了丰富的API和库,使开发人员能够轻松地进行复杂的数据处理和机器学习任务。
4. HBase
HBase是一个面向列的分布式数据库,专门用于存储大规模结构化数据。它具有高扩展性和高可靠性,并且可以提供实时读写访问。HBase与Hadoop紧密集成,可以作为Hadoop生态系统中的一部分使用。
5. Hive
imtoken官网版下载:https://cjge-manuscriptcentral.com/software/66002.html
作者 5G系统之家
相关推荐


教程资讯
系统教程排行
- 1 18岁整身份证号大全-青春岁月的神奇数字组合
- 2 身份证号查手机号码-如何准确查询身份证号对应的手机号?比比三种方法,让你轻松选出最适合自己的
- 3 3步搞定!教你如何通过姓名查身份证,再也不用为找不到身份证号码而烦恼了
- 4 手机号码怎么查身份证-如何快速查找手机号对应的身份证号码?
- 5 怎么使用名字查身份证-身份证号码变更需知
- 6 网上怎样查户口-网上查户口,三种方法大比拼
- 7 怎么查手机号码绑定的身份证-手机号绑定身份证?教你解决
- 8 名字查身份证号码查询,你绝对不能错过的3个方法
- 9 输入名字能查到身份证-只需输入名字,即可查到身份证
- 10 凭手机号码查身份证-如何快速获取他人身份证信息?

系统教程
-
标签arclist报错:指定属性 typeid 的栏目ID不存在。